Player Strategy Imitation
Summary
Research Topics
Agent AI | Player Imitation | Recurrent Neural Networks | RTS Games | Sparse Rewards
Contributors
Chaima Jemmali | Josh Miller | Abdelrahman Madkour | Christoffer Holmgård | Magy Seif El-Nasr
Description
Imitation learning, the task of training an AI to act as similarly as possible to a particular human, has been studied on multiple tasks (Hussein et al. 2017). However, real-time strategy games, such as StarCraft, present a unique challenge: players pursue complex and shifting strategies based on many decision-making factors. They must choose what buildings and units to build, in what order, and at what times. If we can learn to successfully imitate players in a complex game of this sort, we may not only build more human-like StarCraft AI but also gain generally applicable insights. Robust player imitation could help with automated playtesting, example-driven game AI design, procedural content generation, player modelling, and more.
We began by processing replays from specific StarCraft players. We built features to use as input to our learning algorithms, hand-selecting and combining useful information from the game state. These included information about units and buildings controlled by the players, current resources, and so forth.
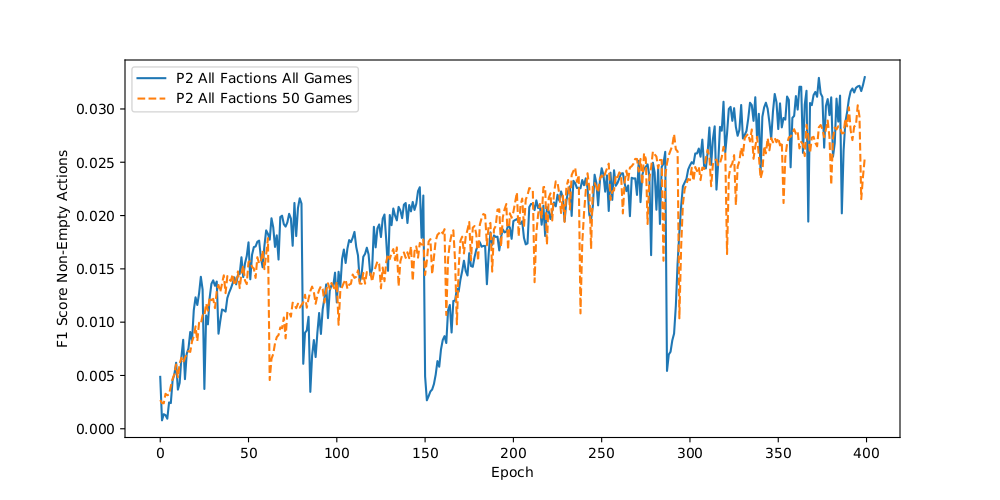
We fed the parsed game states into two different learning algorithms: a recurrent neural network (RNN), specifically a long short-term memory layer (LSTM) followed by a standard linear output layer; and random forests (Ho 1995). RNNs are designed to store and recall information from earlier inputs, making them ideal for learning about sequences of information (Hochreiter and Schmidhuber 1997). By learning to process the game states in order, we could take advantage of this memory to attempt to reconstruct the sequence of unit build actions performed by the player, and then to apply that learning to a new game situation.
In our testing, the RNN was by far the most successful in predicting output actions on a small test set. In an average game, it predicted approximately 30 percent of non-null actions exactly correctly. On the other hand, it also over-predicted many actions near their actual timing, showing low precision. We also measured the "time-warp edit distance," a weighted measurement of the divergence of the sequence of predicted actions from the actual game replay. We found that, after training, we could achieve a fairly small time-warp edit distance on the test set, indicating that our predicted sequence had relatively small magnitudes of mistimed and mispredicted actions. Overall, the RNN showed promise as a starting point for this type of imitation, but it is not a perfect solution.
The next phase of the project is to integrate player imitation learning into an actual StarCraft bot. This would enable us to test our predictions on live games. Showing recordings of these games to experts, we can gain additional insights into how well our player imitation matches a real player's strategies, and how to make it feel more player-like. Further in the future, we hope to expand our imitation learning to include tactical decisions about attack, defense, and unit micromanagement.
Status
In Progress
References
Publications